How the Boehm Garbage Collector Works
The Boehm garbage collector is used by a wide variety of C and C++ programs, and is also used in a number of other language implementations such as D and the GNU Compiler for Java. This article aims to give a high-level overview of how this GC works.
Why the Boehm GC is Special
Most garbage collectors require the cooperation of the programming language or runtime environment to work. They need to identify allocated memory that is no longer reachable from the current program instruction. One common strategy is to follow a trail of pointers – any object that is currently in scope is considered to be reachable, as are any of the other objects that it contains pointers to. The in-scope objects are known as the root set, and by following the pointer trail we can construct our ‘forest’ of reachable memory. Everything else is garbage and will be cleaned up (Figure 1). This approach, however, means that the garbage collector needs to know which pieces of data are pointers and which are plain data.
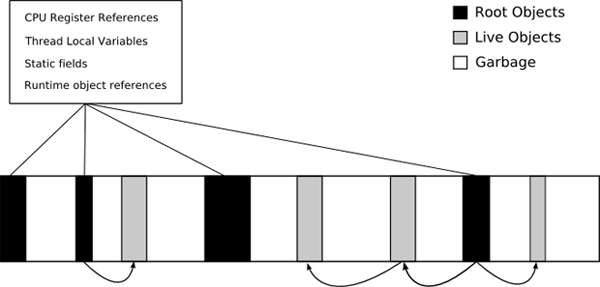
Figure 1: The set of reachable memory. (Image taken from the Mono project’s documentation.)
This strategy works easily in ‘cooperative’ languages like Java – the runtime environment keeps track of the types of the objects and knows which of their properties are pointers to other objects. However, in ‘uncooperative’ languages like C and C++, there is no good way to distinguish pointers from plain data. Pointers are treated as plain integers that we can do arithmetic upon, and plain integers can easily be cast to pointers and used to address memory. Moreover, there are restrictions on how data is laid out in memory; C array elements are guaranteed to be stored contiguously, and C programs often rely on the way that structs are laid out in memory (even though this is not guaranteed as part of the language spec). Storing metadata on the objects to keep track of their types would modify this memory layout. Moreover, it would be a considerable memory and computational overhead to keep track of all these types at runtime. More importantly, most compilers do not provide an easy way to retrieve this type data or to modify the object layout, and even if they did, such changes break binary compatibility and would prevent the program from being linked against libraries that were compiled in the ‘usual’ way.
Despite these challenges, the Boehm GC is able to function without any cooperation from the compiler or the runtime environment. In C, the only adjustment one needs to make is to redirect calls to stdlib’s malloc() / free() to equivalent ones supplied by the Boehm GC. Let us examine how it achieves this feat.
Chunks and Metadata
The Boehm GC manages metadata by housing all allocated objects within ‘chunks’ of memory. These chunks can store one or more objects of equal size, and their headers contain several pieces of metadata, such as the indices of the contained objects that are in use; type information is not included for the reasons outlined earlier. The objects themselves are metadata-free. The GC also maintains a list of addresses of allocated chunks. These chunks are all aligned on a power-of-two boundary, so given a pointer to an object, we can calculate its chunk address simply by masking its low-order bits.
Identifying Pointers in Data
Boehm’s key insight was that simple heuristics allow us to distinguish pointers from data with a high degree of accuracy. As a first approximation, if an integer is greater than the largest heap address or smaller than the smallest one, it can be ruled out immediately. Since the heap is located at the ‘top’ of the address space, most heap addresses are very large integers. Most user data involves relatively small integers, so this first test eliminates many of them.
Next, we wish to check that our candidate address actually points to allocated memory. If it is a valid pointer, masking out its low-order bits would give us the address of the metadata of its containing chunk. This metadata will contain a pointer to the chunk’s entry in the list of allocated chunk addresses (Figure 2). If we were looking at a valid chunk, the entry retrieved from following the metadata-pointer will be an address that points back to the chunk.*
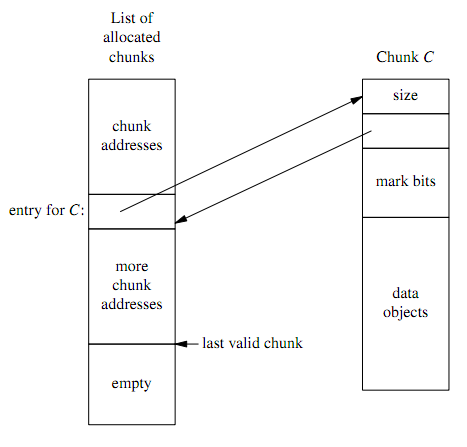
Figure 2: How chunks are managed. Diagram taken from Boehm’s original paper[1].
Finally, the chunk metadata records the sizes of the objects that the chunk contains. If our address is valid, it should be equal to chunk address + k * size of object. If our data passes this test, the GC considers it to be a valid address, and sets a ‘mark bit’ in the chunk metadata to indicate that the object it points to is reachable.
If the GC encounters a candidate address that passes the first test (by falling within the heap’s address range) but fails one of the other two, it adds the address to a blacklist. Further memory allocations will avoid using memory at this address, to minimize the chance that plain data will be treated as a pointer and cause the retention of unused memory.
After repeating this process for every integer in memory, the GC does a final pass (sweep) to see if any chunk has all its mark bits unset. If so, the GC garbage-collects it, removing it from the allocated list and adding it to the free list.
Advantages and Limitations
Clearly, the Boehm GC is not perfect – it can and will leak some memory – but its heuristics ensure that it never frees memory that is still in use. Moreover, since it verifies the chunk address before setting any mark bits, it never modifies user data by accident. By giving up a bit of accuracy, we gain a drop-in garbage collector that works with programs written in any language. Significantly, it does not add any overhead to the operations of the program outside the allocation / deallocation process.
On the other hand, the Boehm GC cannot avoid fragmentation. Fragmentation occurs as memory gets allocated and deallocated repeatedly: over time, this leaves us with many small ‘gaps’ of free space in the heap. These gaps cannot be used unless the program requests a chunk size that happens to fit nicely into them. Garbage collectors in pointer-aware languages deal with this problem via compaction – they separate the allocated and unallocated memory into two contiguous sections on the heap (Figure 3). At the same time, they modify all pointers to allocated memory to point to the new memory locations. However, the Boehm GC cannot do this because it cannot know for sure which pieces of data are actually pointers – we would not want to modify the wrong thing! While this problem is mitigated because the Boehm GC places small objects together in large contiguous chunks, it is not a perfect solution.
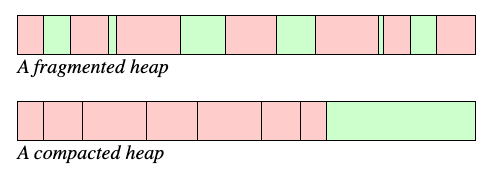
Figure 3: Heap Compaction (red indicates allocated memory)
Garbage Collector as Leak Detector
Although the Boehm GC adds less overhead than other collectors, the marking and sweeping process is still an additional cost that is unacceptable for some applications. However, the Boehm GC is still useful here – it can be used during development to identify leaks! We can drop the Boehm GC into a program that is designed manage memory manually. If it succeeds in finding unused memory to collect, then we know that we have caught a leak.
Performance Improvements
The current implementation of the Boehm GC is both concurrent and generational, which further improves its performance. I may write about the architecture of those aspects in a follow-up note.
References
1: Hans-Juergen Boehm and Mark Weiser. 1988. Garbage collection in an uncooperative environment. Softw. Pract. Exper. 18, 9 (September 1988), 807-820.
2: Hans-Juergen Boehm. Conservative GC Algorithmic Overview. http://www.hpl.hp.com/personal/Hans_Boehm/gc/gcdescr.html